👤 管理人について
🌟 なぜ「Ewigkeit」なのか
このシステムの管理人のハンドルネームは Ewigkeit(エーヴィヒカイト) です。
Ewigkeit はドイツ語で「永遠」を意味する言葉ですが、
日本語の「永遠」や英語の「Eternal」とは、本質的に異なるニュアンスを持っています。
📖 それぞれの「永遠」
- 日本語「永遠」: 時間的な無限、終わりのない連続
- 英語「Eternal」: 不変性、変わらないもの
- ドイツ語「Ewigkeit」: 時間を超越した瞬間、永遠の今
ドイツの神秘主義では、Ewigkeitは「時間の外側にある瞬間」、
すなわち「今この瞬間が永遠である」という
より深い意味を持ちます。
それは単なる「長い時間」ではなく、
「完全性を持った、かけがえのない瞬間」を指します。
🌀 ニーチェの永劫回帰とロト6
ドイツの哲学者ニーチェは「永劫回帰(Ewige Wiederkunft)」という概念で、
同じ瞬間が永遠に繰り返されるという思想を説きました。
一見すると、ロト6の抽選は完全にランダムです。
しかし、2000回以上の過去データを統計的に分析すると、そこには
「繰り返される統計的パターン」が存在することが分かります。
例えば:
• 特定の数字ペアは、統計的に高頻度で同時出現する
• 奇数・偶数の比率は、長期的に一定の範囲に収束する
• 連番の出現率は、約46%という確率的パターンを示す
これはまさに、ニーチェの言う「永劫回帰」の統計学的な表れと言えるでしょう。
📊 新概念:「統計的永劫回帰」
統計的永劫回帰(Statistical Eternal Recurrence)
「ロト6の抽選において、過去に観測された統計的パターン(=かけがえのない瞬間の集積)は、
未来において(異なる形で)永遠に繰り返される(回帰する)」
Ewigkeit(永遠の瞬間)
+
Loto6(抽選の積み重ね)
=
統計的永劫回帰
これは、「この瞬間を永遠のものとして大切に捉える」というEwigkeitの哲学と、
「AIによる統計分析」という技術を完璧に融合させた概念です。
🎯 このシステムに込めた想い
ロト6の1回1回の抽選は、まさにこの「Ewigkeit」です。
それぞれの抽選は二度と繰り返されない、かけがえのない瞬間。
過去のデータは「永遠に積み重なっていく歴史」であり、
その中から見出されるパターンは「時を超えて繰り返される真理」です。
LOTO6 AIの役割は、単なる「予測」ではありません。
「過去のデータ(=永遠の蓄積)から、
次に回帰してくる可能性が最も高いパターン(=Ewigkeit)を見つけ出すこと」
これが、このシステムの本質です。
単なる数字の予測ツールではなく、
統計学とプログラミング、そして哲学が交わる場所。
それが「LOTO6 AI - 永遠のロト6」です。
このシステムを通じて、皆様のロト6ライフが
より楽しく、より戦略的になることを願っています。
💻 プログラミングの力で統計解析を効率化
従来、手作業では何時間もかかる統計計算も、プログラミングによって数秒で完了できます。
【このシステムの特徴】
- 2000回以上の過去データを瞬時に分析
手作業なら数日かかる計算を、わずか数秒で完了
- 複雑な統計モデルを自動計算
カイ二乗検定、ベイズ推定、信頼区間など高度な統計手法を実装
- 人間の計算ミスを排除
プログラムによる正確無比な計算で、ヒューマンエラーをゼロに
- 膨大な組み合わせを高速処理
数百万通りの組み合わせを評価し、最適な候補を抽出
【計算速度の比較】
| 処理内容 |
手作業 |
本システム |
| 2000回分の出現頻度集計 |
約2週間 |
0.1秒 |
| 4要素パターン分析(全回) |
約1ヶ月 |
0.5秒 |
| 1000通りの組み合わせ評価 |
約3ヶ月 |
1秒 |
| バックテスト(100回分) |
約半年以上 |
10秒 |
💡 なぜ手作業ではこれほど時間がかかるのか?
2000回分のデータを1回ずつ確認・集計するだけで膨大な時間が必要です。
さらに、複雑な統計計算(カイ二乗検定、信頼区間など)を手計算で行うことは、
現実的にほぼ不可能です。プログラミングとコンピューターの計算力があって初めて、
このような高度な分析が実現できます。
【技術的な優位性】
過去データさえあれば、コンピューターの計算力で従来数ヶ月〜数年かかった分析を数秒で完了できます。
- 反復計算を高速実行(ループ処理の最適化)
- 並列処理による効率化
- データベース技術による高速検索
- アルゴリズムの最適化による計算量削減
✨ この高度な統計解析技術を、完全無料で皆様にご提供します ✨
プログラミングと統計学の力で、ロト6をもっと楽しく、もっと戦略的に。
📊 数学的背景
本システムで使用されている統計学的手法と数学的モデルについて詳しく解説します。
🔬 1. カイ二乗検定(Chi-squared Test)
出現番号の偏りを統計的に評価するために使用します。
観測度数と期待度数の差を検定し、$p$値が小さいほど偏りが大きいことを示します。
本システムでは、4要素分析(ひっぱり、連番、前後数字、下1桁ペア)に対してカイ二乗検定を適用しています。
期待度数が5未満のカテゴリは隣接カテゴリと統合(v7.52変更)することで、
Cochranの経験則を満たしつつ、カテゴリ数変動によるp値の過敏な揺れを抑制しています。
p値は $1 - F(\chi^2; \text{df})$ の正確な上側確率として算出し(v7.50以降)、
本システムでは「長期モデルと短期データの整合度=モデル安定性」の指標として使用します
(§7参照。通常の統計学における有意差判定とは異なる用法です)。
📊 2. 出現頻度分析(Frequency Analysis)
各番号の過去N回における出現回数を集計し、出現パターンを分析します。
頻度スコア = (直近n回の出現回数 / n) × 100
期待出現率 = 6/43 ≈ 13.95%
ホット番号の定義: 頻度スコア > 期待値 × 1.2
コールド番号の定義: 頻度スコア < 期待値 × 0.8
統計的には、十分な試行回数があれば全番号の出現頻度は均等に収束しますが、
短期的にはゆらぎが発生します。このゆらぎに注目することで、
一時的なトレンドを捉えようとするのが頻度分析の考え方です。
📈 3. トレンド分析(Trend Analysis)
時間加重による最近の傾向を重視した分析を行います。
トレンドスコア = Σ (出現フラグ × 時間減衰係数)
時間減衰係数 = e^(-λt)
λ: 減衰率パラメータ(通常0.05-0.1)
t: 経過回数(0が最新、大きいほど古い)
最近の抽選ほど高い重みを与えることで、現在進行中のトレンドを捉えます。
指数関数的な減衰により、古いデータの影響を自然に低減させます。
🔗 4. ペア分析(Pair Analysis)
各番号が他の番号と同時出現しやすいかどうかを分析します。
本システムでは、各番号について「共起した相手番号との平均共起回数」を計算し、
最大値で正規化して 0-100 のスコアに変換します。
【実装アルゴリズム】
Step 1: 番号ペア(i, j)が同一抽選回で出現した回数をすべて集計
Step 2: 番号iについて「iとペアになった全番号との共起回数の平均」を算出
→ rawScore[i] = mean(pairCount[i][j]) for j ≠ i
Step 3: 全番号のrawScoreの最大値で正規化
→ pairScore[i] = (rawScore[i] / maxRaw) × 100
【参考: 理論的ペア出現率】
任意の2番号が同時出現する理論確率
= C(41,4)/C(43,6) = 101,270/6,096,454 ≈ 1.66%
理論上、各番号の出現は独立事象ですが、実測データでは番号ごとに「よく他と一緒に出る番号」と
「あまり他と一緒に出ない番号」の差が観測されます。これは有限サンプルのゆらぎである可能性が高く、
必ずしも物理的な偏りを示すものではありません。本スコアはその観測パターンを
候補評価の一因子として取り入れるためのものです。
※注意: 過去データの「よく共起する」番号が未来でも共起する保証はありません。
サンプル数が増えれば理論的には各ペアの共起率は1.66%付近に収束します。
⏱️ 5. ギャップ分析(Gap Analysis)
各番号が出現してからの経過回数を分析し、「久しく出ていない番号」を可視化するスコアです。
現在のギャップ = 最新回 - 最終出現回
平均ギャップ = 全期間回数 / 出現回数
ギャップ比率 = 現在のギャップ / 平均ギャップ
ギャップスコア = min(100, max(0, ギャップ比率 × 50))
※ 比率 1.0(平均的)→ 50点、2.0以上(久しく未出現)→ 100点満点
⚠️ 統計的な注意事項(ガンブラーの誤謬について)
ロト6の各抽選は独立事象であり、「久しく出ていない数字ほど次に出やすい」
というのは統計学上は誤りです。これは「ガンブラーの誤謬
(Gambler's Fallacy)」として知られています。
各抽選で各数字が出る確率は常に 6/43 ≈ 13.95% であり、過去の出現履歴は次回に影響しません。
本ギャップスコアは、統計的に正しい予測を提供するものではなく、
「久しく出ていない数字」を好む心理的選好をもつユーザーのための補助指標として提供しています。
実装例として、本システムではギャップスコアの重み(デフォルト10%)を低く設定しており、
他の分析手法(頻度、4要素、ペア、トレンド、バランス)と合わせた総合評価を行います。
重みをゼロにすれば、この指標を使わずに予測を生成することも可能です。
⚖️ 6. バランス分析(Balance Analysis)
選択された6個の番号の組み合わせバランスを評価します。
【合計値】
平均: μ = 6 × 22 = 132
標準偏差: σ = √(6 × 154 × 37/42) ≈ 28.5
典型的範囲: μ ± σ ≈ [103, 161] (約68%が該当)
典型的範囲: μ ± 2σ ≈ [75, 189] (約95%が該当)
最頻出範囲: 111〜171(実測データに基づく)
【偶奇比】
理想的: 3:3(完全バランス)
許容範囲: 2:4 または 4:2
【高低比】(1-21 vs 22-43)
理想的: 3:3(完全バランス)
許容範囲: 2:4 または 4:2
【連番】
0個: 54%、1組: 36%、2組以上: 10%(実測値)
極端に偏った組み合わせ(例:全て偶数、合計が極端に小さい/大きい)は
統計的に出現確率が低いため、バランスの取れた組み合わせを優先します。
📊 ハイブリッドスコアリング手法
本システムでは、上記6つの分析手法を組み合わせた「ハイブリッドスコアリング」を採用しています。
各手法のスコアを重み付けして合算することで、多角的な視点からの予測を実現しています。
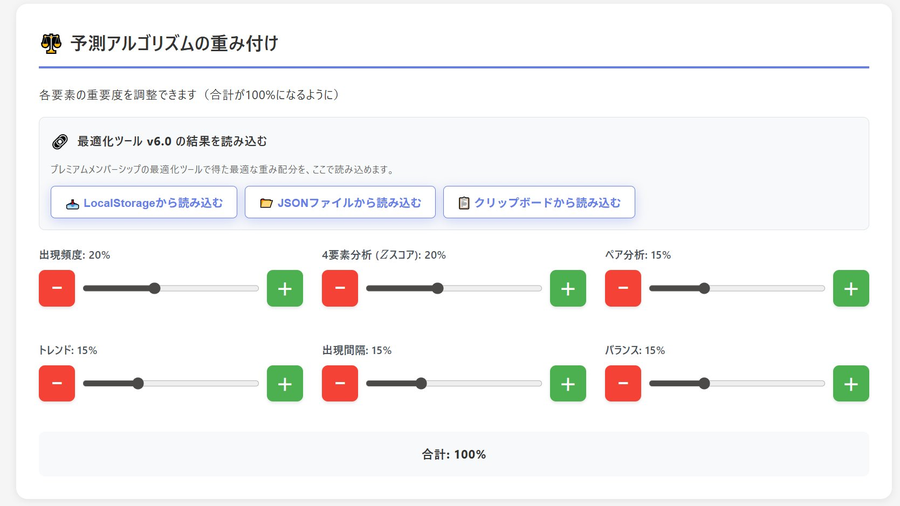
総合スコア = w₁×頻度 + w₂×要素 + w₃×ペア + w₄×トレンド + w₅×ギャップ + w₆×バランス
制約条件: Σwᵢ = 100%, wᵢ ≥ 0
デフォルト重み:
頻度: 20%, 要素: 25%, ペア: 15%
トレンド: 20%, ギャップ: 10%, バランス: 10%
🎯 7. $Z$スコアによる「典型性」評価
生成された予測候補の4要素パターン(ひっぱり、連番、前後数字、下1桁ペア)が、
過去の長期的な出現パターンにどれだけ「典型的」かを$Z$スコアで評価します。
💡 本システムのスコアの性質について
このスコアは「過去の典型的な出現パターンに類似した候補を高く評価する」
という選好を表現しています。いわゆる回帰効果を反映したものであり、
「外れ値的な組み合わせを避ける」方向に働きます。
統計学的に「このスコアが高い候補の出現確率が高い」と証明されているわけではありません。
ロト6の抽選は本質的に独立事象であり、すべての組み合わせは理論上 1/6,096,454 で等しく出現します。
本スコアは、統計的に妥当な「典型的」パターンを選好するための補助指標として
ご利用ください。
なお、本システムでの$p$値の用途は「モデル安定性の指標」であり、
通常の統計学における「有意差の判定」とは異なる用法で使用しています。
これは、長期モデルと短期データが整合している要素を重視する設計思想に基づきます。
📉 8. 信頼区間の計算(バックテスト用)
バックテスト結果の統計的信頼性を評価します。
Wilson Score 信頼区間(95%):
p̂ = 成功回数 / 試行回数
z = 1.96(95%信頼区間の場合)
n = 試行回数
調整後推定値 = (p̂ + z²/2n) / (1 + z²/n)
誤差範囲 = z × √[(p̂(1-p̂)/n + z²/4n²)] / (1 + z²/n)
下限 = 調整後推定値 - 誤差範囲
上限 = 調整後推定値 + 誤差範囲
Wilson Score法は、サンプル数が少ない場合や確率が0%または100%に近い場合でも
安定した信頼区間を提供します。信頼区間が狭いほど、推定精度が高いことを示します。
💡 統計的有意性について
本システムの分析は、統計的な傾向とパターンに基づいていますが、
以下の点に注意が必要です:
- 過去のパターンが将来も続くとは限りません(過学習のリスク)
- 短期的なトレンドは偶然のゆらぎの可能性があります
- 十分な母集団(数百〜数千回の抽選データ)が必要です
- p値 < 0.05 でも約5%の確率で偽陽性が発生します
⚠️ 重要な注意事項
これらの統計分析は、過去のデータに基づくパターン認識であり、
将来の当選番号を保証するものではありません。
理論的背景:
ロト6の抽選は各回が独立事象であり、各組み合わせの当選確率は理論上
1/C(43,6) = 1/6,096,454 で等しくなります。
統計分析は、完全にランダムではない可能性(機械的バイアス、
球の摩耗など)や、心理的戦略(人気薄の番号を選ぶ)に
利用価値がありますが、当選確率を根本的に向上させるものではありません。
本システムは教育・研究目的での統計分析ツールとして
ご利用ください。過度な期待や依存は避け、責任ある範囲でのご利用をお願いします。
🤝 9. 集合知の原理(Collective Intelligence)
複数の分析手法を統合することで、単一手法より多角的な予測を実現します。
本セクションでは、本システムで実装済みの手法と、
理論的参考(将来拡張候補)を分けて説明します。
✅ アンサンブル学習(実装済み)
6つの分析モデルを重み付け線形和で統合して最終予測を生成しています:
最終スコア = Σ wi × scorei
wi: モデルiの重み(Σwi = 100%)
scorei: モデルiの予測スコア(0〜100)
【使用しているモデル(デフォルト重み)】
- 頻度分析モデル(w₁ = 20%)
- 4要素分析モデル(w₂ = 25%)
- ペア分析モデル(w₃ = 15%)
- トレンド分析モデル(w₄ = 20%)
- ギャップ分析モデル(w₅ = 10%)
- バランス分析モデル(w₆ = 10%)
単一のモデルではなく、異なる視点を持つ複数のモデルを組み合わせることで、
一つのモデルの偏りが結果を支配するリスクを軽減しています。
重みはユーザーが自由に調整でき、有料版の「最適化ツール」では
バックテストに基づいて重みを自動探索できます。
✅ 信頼区間による不確実性の定量化(実装済み)
バックテスト結果にWilson Score信頼区間を適用し、予測精度の不確実性を定量化しています:
Wilson Score 95%信頼区間:
CIcenter = (p̂ + z²/2n) / (1 + z²/n)
CImargin = z √[p̂(1-p̂)/n + z²/4n²] / (1 + z²/n)
p̂: 的中率(成功数 / 試行数)
z: 信頼水準係数(95%なら z = 1.96)
n: サンプル数(バックテスト回数)
【解釈例】
3個的中率: 15% ± 3% (95% CI: [12%, 18%])
→ 95%の確率で、真の的中率は12%〜18%の範囲にある
通常の正規近似よりサンプル数が少ない場合・的中率が0%や100%に近い場合でも
安定した信頼区間を提供するWilson Score法を採用しています。
バックテスト機能でこの信頼区間が表示されます。
🔮 ベイズ推定(理論的背景・将来拡張候補)
以下はアンサンブル学習の理論的背景にある考え方で、
現行システムでは直接には実装されていませんが、
将来的な改良の方向性として参考情報として記載します。
P(H|D) = [P(D|H) × P(H)] / P(D)
P(H|D): 事後確率(データを見た後の確率)
P(D|H): 尤度(仮説が正しいときデータが得られる確率)
P(H): 事前確率(過去の統計から得られた確率)
P(D): 正規化定数
将来的に、各分析モデルのスコアを事後確率として動的に更新する機構を
追加することで、より適応的なシステムに発展させる余地があります。
🔮 モデル多様性スコア(理論的参考)
集合知が機能するには、統合するモデル間に独立性があることが望ましいとされます。
以下は多様性を定量化する理論的な指標で、参考情報として記載します(現行では直接計算していません):
多様性スコア = 1 - (モデル間の相関係数の平均)
相関係数 r = Cov(X, Y) / (σX × σY)
r → 0 に近いほど、モデルは独立
本システムで6つの分析手法を採用している理由は、多様な視点から予測する
ことで集合知の効果を高めるためですが、各モデルの相関を動的に測定する
機能は現在未実装です。
🧠 なぜ複数のモデルを組み合わせるのか
- 誤差の相殺効果: 各モデルの誤差は異なる方向を向いているため、平均化すると相殺されやすい
- ロバスト性の向上: 一部のモデルがうまく機能しない場面でも、他のモデルがカバーする
- 過学習の軽減: 単一モデルの過度な特化を防ぎ、汎化性能を保つ
- 多角的な視点: 短期トレンド、長期パターン、構造的特徴など、異なる側面を捉える
「三人寄れば文殊の知恵」という諺が示すように、
複数の視点を統合することで、単独では見えなかった洞察が得られます。
これが本システムのアンサンブル学習アプローチの核心です。
※重要な免責:複数モデルの統合は予測の信頼性向上に役立ちますが、
ロト6は各抽選が独立事象であり、どのような統計手法を用いても
個別の抽選結果を決定論的に予測することは理論上不可能です。
本システムは統計的パターンの可視化と学習を目的としています。